Bazaar-Notes
From Java4c
@ident=Bazaar_notes
Links:
- Bazaar-guide: a guide to use Bazaar.
This size is in german, because it is discussed in a german team. It will be presented in english in the future. TODO
Contents |
[edit] Kurzer Abriss, Arbeit mit MKSSI, git, mercurial, Bazaar
Hartmut: MKSSI ist seit über 10 Jahren bei mir in Gebrauch.
- Nur auf Arbeit, zentrale Administration,
- Die MKSSI-Software wird normalerweise nicht ständig updated. Das Arbeiten ist nicht sehr schnell, eher etwas für ordentliche Pflege.
- Wird gemacht, für die Versionen, die herausgegeben werden. Nicht für stündliche kleine Änderungen. Da wäre der Arbeitsaufwand zu hoch.
Hartmut: git war das erste der 'dritten Generation' für mich.
- Geht ganz gut, init commit, alles ganz einfach
- Nachschauen der Änderungen: Hier ist die GUI (gitk) nicht sehr bedienerfreundlich. Die schnelle Tastaturbedienung ist mangelhaft, der Tastaturfokus ist im falschen Teilfenster. Immer mit Maus schieben ...
- Linux-like cmdline-Bedienung auf Windows-PC ist für mich eher interessant.
Hartmut: mercurial - ähnlich wie git, nur eher für windows, eigentlich sehr ähnlich git.
Hartmut: Bazaar gefällt mir persönlich wegen der GUI besser.
Hartmut: Alle drei Systeme sind aber funktionell eher ähnlich. Ich pflege Quellen in Bazaar, um sie dann auch in hg zu committen, mit selbigem commit-Text wie in Bazaar zuvor zusammengestellt. Das ist nur ein Aufruf. Ein Hg-Archiv beispielsweise für CRuntimeJavalike liegt auf [bitbucket.org/jchartmut/cruntimejavalike]. Hg deshalb, weil die bitbucket-Seite nur hg unterstützt. Der Aufwand, in hg doppelt zu pflegen, ist kaum erhebenswert.
- Commit-Text zusammenstellen
- Vorderhand geht es beim Commit-text darum: Was leistet diese Version insgesamt, unterschied zur Vorversion. In der Zweiten Linie geht es aber um die Änderung in den einzelnen Files.
- Sind im Commit sehr viele Files enthalten, dann handelt es sich meist um das Ergebnis eines Refactoring wegen einer Änderung. Solche Änderungen brauchen in den Quellfiles nicht vermerkt werden, zuviel Aufwand, uninteressant.
- Sind dagegen wenige Files geändert, dann lag meist auch eine Änderung der Funktionalität vor. Diese sollte unabhängig vom Commit in den Quellfiles notiert werden. Hier hilft aber die Differenzanzeige, um während des Commit die Änderungen in den Files zu vermerken. Man kann einen passenden Commit-Text zusammenstellen, dabei die Änderung der Einzelfiles betrachten und dabei in den Einzelfiles Änderungen notieren (log des Files).
- Ein automatisches Eintragen der Änderung in den Files aus dem checkin-Textes aus der Arbeit mit dem Source-Integrity-System produziert meist Einträge in den Files, die die Änderungen schlecht abbilden. Das liegt daran, weil der Arbeitsaufwand für jeden Einzelfile zu hoch ist. Dieses automatische Eintragen ist aber eine häufig verwendete oder voreingestellte Methode bei MKSSI & co.
- Der Arbeitsaufwand bei manuellem Eintragen in den File ist deshalb bei Bazaar geringer, weil
- Es gibt eine schnelle Übersicht, welche Files betroffen sind. Einfacher Knopfdruck für Viewdiff. Man kann schnell auswählen, bei welchen Files ggf. gleiche Einträge überhaupt notwendig sind. Nicht bei allen geänderten.
- Mit den Files, die keine wesentlichen Änderungen enthalten sondern nur Anpassungen an Änderungen anderer Files, braucht man sich also gar nicht beschäftigen.
- Die Änderung im File eingetragen und per Zwischenablage auch im Commit-Text abgelegt ist dann eigentlich nur einmaliger Aufwand, nicht zweimal.
- Wenn es wesentliche Änderungen sind, dann ist die Beschreibung der Änderung auch ein schöpferischer und nicht formeller Akt. Dann lohnt es sich auch, die entsprechend notwendige Zeit aufzubringen. Möglicherweise wird man bei der Änderungsbeschreibung im File auch noch weitere dabei entdeckte Pflegekorrekturen anbringen, die insgesamt die Quelle weiter aufwerten. Dann hat es sich sowieso gelohnt.
[edit] Source Content Management oder hart archivieren? Nur Quellen im SCM?
Eine harte Archivierung ist das Verpacken der Files auf einem Datenträger. Da das Zip-format sich als langjährig beständig erwiesen hat, kann man ganze File-Bäume zippen und irgendwo aufheben.
Nachteil: Keine Unterstützung für Diff-View außer auspacken und mit einem Diff-tool vergleichen. Der Total-Commander eignet sich dazu allerdings recht gut, da er in beiden Paneelen in zip-Archive tief eintauchen kann.
Vorteil: Unabhängig von einem Tool, die Files einer Version sind zusammengebunden einfach da. Es hat sich schon oft als günstig erwiesen, lange Jahre zurückliegende Files nicht mit den damaligen Tools aufrollen zu müssen sondern einfach entzippen.
Der Vorteil für die Langjährigkeit sollte bedacht werden.
=>Schlussfolgerung: Ab und zu zippen und wegpacken, mindestens bei wichtigen Releaseständen. Aber unnütze zipfiles auch mal löschen.
=>Schlussfolgerung: Für akutelle Softwareentwicklung jedenfalls ein Source-Integrity-Tool nutzen, Zippen nur zusätzlich.
[edit] Verzeichnissstuktur-Rückschluss
Sowohl für das Zippen als auch für Sourcenpflege, Sourcenaustausch usw. liegt der tatsächliche Umfang von Sources insgesamt meist in einem Bereich von wenigen Megabyte. Damit ist der Datenaustausch mindestens erleichtert. Wenn man in die selbe Verzeichnisstruktur in der Quellen liegen noch hineintue:
- Objects
- erzeugte executable und umfangreiche Datenbasis-Files (Visual Studio ncb-Files und dergleichen)
- logfiles, Output-Files beim Testen
- alte Archive (zips)
dann springt der Umfang des Verzeichnisbausms von wenigen Megabyte ganz schnell auf -zig Megabyte. Das Problem merkt man
- beim zippen (ganz schnell mal ablegen zum späteren Vergleich)
- beim Vergleichen (alle Obj erscheinen als geändert, alles rot, erst mal schaun was das ist)
- bei der Pflege der Sources in einem SM-system (Source Management): viele nicht erfasste files: Sind die wichtig? Ach, sind nur Obj, doch ein wichtige wird übersehen.
=>Schlussfolgerung: Möglichst Sources von Testfiles und Executables trennen. Die wenigen Files, die nicht trennbar sind (weil die Tools sie ins aktuelle Verzeichnis legen), in einer ignore-Liste erfassen, ggf. beim zippen ausschließen usw. Sind es wenige, dann sind sie verwaltbar
- Object-Files auf einem tmp-Ordner speichern
- Generierergebnisse neben dem Source-Baum speichern.
[edit] Archivieren von Executables
Aus oben genannten Gründen sollten die Libs und Executables nicht mit den Sources im SM gemischt werden.
- Die libs und executables könnten einerseits immer aus den Sources generiert werden (wenn alles richtig ist)
- Die libs und executables sind nicht vergleichbar mit üblichen diffs.
- Die libs und executables sind im Code-Umfang zu hoch.
Es ist aber wichtig, libs und exe im Zusammenhang mit einem Checkpoint der Sources zu speichern.
- Als Auslieferungsstand
- Als wichtigen Teststand für Rückrüsten, möglicherweise ein Kandidat für Auslieferung.
Lösung:
- Beim committen eines guten Standes, der angetestet ist, ein kleines batch laufen lassen, das die exes lokal kopiert mit Datumskennzeichnung.
- Damit sind mehrere exes mit Datumsverbindung zum commit lokal vorhanden. Es kann getestet werden.
- Auslieferung: Executables und ggf. libs als zip abspeichern,, siehe oben. Dabei auf den Stand zugreifen, der vorher lokal kopiert wurde und garantiert aus den Sources, die committed wurden, erstellt wurde.
- Nur bei Master-Releases, die entgültig ausgeliefert werden, sollte folgeder Aufwand getrieben werden: Nach erfolgreichem Test die Quellen auf Produktgenerierungsrechner von anderer Person auschecken, neu compilieren, neues Generat erstellen und nochmals testen. Diese Vorgehensweise sichert die Konsistenz der Quellen mit dem Generat und dürfte bei Auslieferungen wichtig sein, dauert aber in der täglichen Fortschrittsarbeit einfach zu lange.
[edit] More as one Repository for one product
@ident=multiBzr
- Products with more as one components.
- Products are build with more as one components. Any component should be independent from the concretely product, tested as 'component' and may be used in more as one product.
- Conclusion: Do not mix sources, separate it. Therefore any component needs its own bzr archive.
- Sources of components should be located in a subdirectory of the product source tree. It is helpfull to use sub-directories to keep tidiness.
- In linux the sub directory may be a symbolic link. It means, the sources are located anywhere other in the file tree really and they can be maintained outside of the products source tree. In windows a real copy is necessary. But note, that a tool can often gotten the sources from any pathes in the file tree. It is a problem of absolute pathes versus a local sandbox.
- Conclusion: The .bzr repositiory of a component should be located in a sub directory of the product source tree.
- The name of the sub directory should, but doesn't need be identical with the name of the component.
- Getting of source tree of a component, getting its bzr archive
To get the bzr repository for a component of a product, use a simple batch or script file inside the product file tree in that directory, where the components root directory should be stored.
srcJava_Zbnf/ ..... This is the components directory, where its srcJava_Zbnf/.bzr should be located. getBzr_srcJava_Zbnf.bat ..... This is the batch file to get the bzr archive of the component.
The batch file contains the simple line:
bzrGetVersion srcJava_Zbnf 59
This line should be kept simple and independent of any operation system. Note, that the batchfile works under linux too, if it is set 'executable'. The batchfile calls another script, 'bzrGetVersion' and names the storing directory and the requested version.
The bzrGetVersion scriptfile should be located anywhere in the PATH of the computer. It is a thing of installation, not a thing of the designated sources of the concrete product. It contains - for windows - and should be adapted to the concretely conditions at the PC-installation:
@echo off REM How to get a component's sources: REM The sources are contained in an bzr archive. REM The bzr archive is an distributed repository. REM An archive can exist as a copy on several places, REM for example at a external hard disk or in network or as a local copy in another drive. :: REM This is the path to all archives for this computer, correct it if necessary: set BZR_ARCHIVEPATH=D:/Bzr :: REM The batch renames the current directory if it is existing yet: if not exist %1 goto :noCurrent if exist %1.old rmdir /S/Q %1.old if exist %1.old goto :nodelOld ren %1 %1.old if exist %1 goto :noRename :noCurrent :: REM copy the bzr archive and resynchronize all members with the required revision echo on bzr checkout %BZR_ARCHIVEPATH%/%1 %1 -r %2 @echo off if not exist %1 goto :noBzr goto :ende :: :noRename echo can't rename %1 to %1.old. It may be used yet. Do it manually! pause goto :ende :: :nodelOld echo can't delete %1.old. It may be used yet. Do it manually! pause goto :ende :: :noBzr echo The bzr archive is not pulled. The version may be faulty or the source path of bzr does not exist. echo See error messages above. pause :ende exit /B
If you follow the command statements, you can see that an existing directory is kept, of found, but the directory of the component is get newly anytime. It assumes that all bzr archives are located in one directory in the file tree, which can be an external disk too or an network path. See 'BZR_ARCHIVEPATH'.
The content of the archive will be cloned with the 'bzr checkout' command. The files are resynchronzed therefore. An independent working with the files and the cloned archive is possible, if necessary. The working can be pushed to its parent later using 'bzr push', 'bzr merge' etc. But in most cases only the resynchronized version of files are need.
[edit] Mehrere Produkte aus einem Repository
Das große Thema ist Wiederverwendung (Reuse). Häufig zu Beobachten: Reuse besteht aus copy'n paste and change. Die Quellen wandern also irgendwo anders hin, bzgl SCM auch für den einzelnen besser zu beherrschen - man muss sich nur mit dem beschäftigen, was man selbst hat.
Das ist keine wirkliche Wiederverwendung. Der wirkliche Vorteil des reuse geht dabei verloren:
- Fehler, die in Produkten festgestellt werden, werden in den jeweiligen Modulen korrigiert und sind dann automatisch auch für andere Produkte mit korrigiert, obwohl sie dort ggf. noch gar nicht aufgefallen sind.
Für true-reuse ist es notwendig, die Software-Module so zu bauen, dass sie unverändert in verschiedenen Produkten verwendbar sind und das Änderungen für alle Produkte nutzbar sind. Das ist eine Frage der Schnittstellen. Die Schnittstellen sind viel wichtiger als die innere Funktionalität. Letztere kann man immer noch verbessern. Schnittstellenänderungen sind kritisch. - Andererseits sind Schnittstellenänderungen auch verträglich, wenn sie formell adaptiert werden können.
Ein shared-Repository in bazaar scheint die Lösung zu bieten, aus einem recht großen Quellenumfang für verschiedene Komponenten verschiedene Quellen herauslösen zu können. Die Komponenten haben selbe gemeinsame Quellen, ggf. in verschiedenen Revisionen, die aber immer abgeglichen werden können sollten. Die Komponenten sind dann Basis für ein Produkt. Komponenten existieren in Form von libs oder jars in Java und können eigenständig getestet werden:
Quellen Komponenten Produkte
viele ===> weniger ===> aus Komponenten
verschiedene überschaubar und Produkt-spezial-Quellen
gebaut.
Wie funktioniert shared-Repository als zentraler Bezug - bin beim testen. (Hartmut)
[edit] Zentrale Ablage für Repositories
@ident=centralRepos
Man kann immer und überall Repositories haben. Behält man den überblick und synchronisiert diese gegenseitig (push, pull), dann gibt es auch nicht zuviele Seitenzweige.
Jedoch, arbeiten viele Leute mit den Repositories, auch weniger eingeweihte, einfache Nutzer, anderes Problem Archivierung, langjähriges aufheben: Dann sollte an einer definierten Stelle das Master-Repository stehen. Jeder Quellenbearbeiter hat die Pflicht, sich mit dem Master-Repository abzustimmen, also seine Änderungen zu pushen oder von dort zu pullen. Gegebenenfalls sollte eine Person mit der Pflege des Master-Repositories beauftragt sein. Mindestens bei Releaseständen muss diese Person dort bereinigend eingreifen.
[edit] Creating one shared repository in the local space
The local space means any external hard disk, network folder or such which is owned by one person, by me. It is my local space, which can be used from some more people in my direct environment.
For any component of sources one shared repository should be created one time. On one sub directory per component: bzre: Bazaar -> Start -> Initialize: (x) Shared repository. An existing plain branch can be pushed to them.
[edit] Creating a branch for working
- Create a new plain branch at the working position: bzre: Bazaar -> Start -> Initialize: (x) Plain branch.
- Pull from a shared repositiory: Button Pull, select the shared repository, select a branch.
- If there are some files already, create the branch at a new position and then move .bzr subdir.
[edit] Branches und dessen Auflösung
@ident=.branch
- Viele Seitenzweige wegen unterschiedlichen Korrekturen
- Man kann sich auf den Standpunkt stellen, bei Korrekturen für kundenrelevante Software jeweils nur das aufgetretene Fehlerbild zu behandeln, alle anderen Softwareteile unverändert zu lassen. (Do not touch a running system). Das ist eine weit verbreitete Vorgehensweise. Folge sind dann sehr viele Seitezweige, die kaum mehr zusammenfließen.
- Primär ist diese Vorgehensweise richtig.
- Es zeigt sich aber, dass eine Änderung in Quellen, auch Restrukturierung, häufig zwar Nacharbeiten erforderlich macht. Diese Nacharbeiten sind aber formal abhandelbar. Man braucht nicht an jeder Stelle einer notwendigen Adaption an geänderte Quellenstände nachzudenken sondern muss nur den Compiler befragen. Kommt keine Fehlermeldung, ist alles in Ordnung. Eine Fehlermeldung soll mit formellen anschauen von Aufrufargumenttypen usw. behebbar sein, ohne dass man in die eigentliche Funktionalität einsteigt. Ist eine solche Nacharbeit möglich, dann kostet diese nur die Zeit der Pflege der Quellen, keine extra Testzeit. Zudem kann die Quellenpflege von jemanden ausgeführt werden, der zwar sehr gute Kenntnisse von Quellen und COmpiler hat, aber keine Tiefenkenntnis für die jeweilige Anwendung haben braucht. Man kann also delegieren.
- In diesem Sinn ist eine Adaption eines Produktes an veränderte Quellen der Komponenten möglich und zweckmäßig. Mann kann dann eher an einem Hauptzweig arbeiten.
- Schlussfolgerung: Schnelle Änderungen ->Seitenzweig, Auflösen dessen, Änderung in Hauptzweig einfließen lassen und Adaption des Produktes auf Hautpzweig der Komponenten ausführen.
[edit] Side branches
less experience
bzr checkout ../masterlocation . -r REVNR
Gets a part of trunk untio REVNR. It is similar
bzr revert -r REVNR
What is the difference???
bzr update ../masterlocation .
This copies all files in the current dir. It seems to destroy the older-revision side branch (?)
Is there a possibility to checkin changes based on a older revision, without any merge. Only the changed files based on the older revision should be stored in the bazaar repositiory - to compare with other versions or look for changes later. Background: Changing of some source files to bugfix an older software. The reason is not develop and merge.
The workflow of develop and bugfix in a decentralized team is explained in
But this is not the problem of side branches, more the problem of development in team.
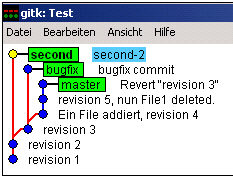
An side glance to git:
$ git branch bugfix
creates a branch named 'bugfix' in the same only one repository. It is a branch with the same revision as the current one.
$ git checkout bugfix
now switches to the named branch.
$ git reset -q COMMITNR
This moves the current revision of the current branch (it is 'bugfix' to a older revision. COMMITNR is the hash number of any commit, see git log
$ git checkout .
resynchronized all files of the selected revision.
...changing any files and
$ git commit
builds a side branch in the repository (archive).
Now a switch to another branch and its revision is possible in the same sandbox to work with it:
$ git checkout master
now switches back to this named branch and resynchronizes all files. Work with it, commit etc.
If there should be worked only at one side branch to any time, and be worked at another side branch to another time, then only one sandbox is necessary. You can switch between the branches. The files are changed, all files are stored in the git archive.
If there should be worked with more as one side branches to the same time, a copy of the git archive is necessary. The archive and the files should be stored at different places on the hard disk, or at more as one computer etc. It isn't recommended to use the same git archive, may be with an symbolic link in linux. The disadvantage is: The git archive knows the current branch, which was selected with 'checkout'. If you want to use only one archive but more as one sandbox for the files, you can have a symbolic link in the sandboxes to the same archive. But then you have to switch between the side-branches before any status, commit etc. action are done in one of the sandboxes. But be attentive to your files. You may overwrite they if you are careless. You can't do that at the same time, maybe more as one people in network. It will be confused if they are work concurrently.
I haven't test yet, but it shouldn't a problem to merge the more as one git archives without conflicts, if only one archive has changed only one side branch.
[Image: example side branches in git]
Now back to bazaar:
John A Meinel proposed the following answer:
If you want to commit new changes based on an older revision, you generally want to start a new branch. So something like
bzr branch master feature -r OLD cd feature bzr commit
If you are using a checkout you can do
cd checkout bzr branch --switch -r OLD ../master ../feature
TODO test

{kind=link}